弱文脈依存文法にまつわる理論言語学のはなし
近年、計算言語学・NLPの方で、言語モデルの評価の文脈や、自然言語の統計的普遍性に関する研究の文脈で、自然言語の文法の生成力に関する議論が再注目されているように思われます。 生成力に関しては、理論言語学の知見が今に至るまで少しずつ着実に積み重ねられているものの、情報源が少なすぎるので、これまでの議論と関連研究をまとめて置いておきます。
自然言語は弱文脈依存言語なのか?
用語や歴史の説明は抜きにして、結論から言うと、自然言語の文法が弱文脈依存文法(Mildly Context-Sensitive Grammar; MCSG)であるということは明確に示されているわけではありません。
ただ、少なくとも以下の2つの事実から、「自然言語の文法は弱文脈依存文法である」という言説には一定の合意が得られています。そのため、しばしば弱文脈依存仮説(MCS Hypothesis)などとも呼ばれています。
なお、mildly context sensitiveという用語・概念は Joshi (1985) が初出です。
1. 文脈自由文法では表現できない構文が自然言語に存在する。
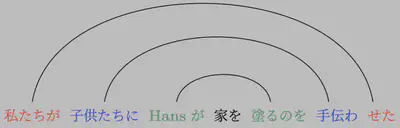
Shieber (1985) により、Swiss-German(ドイツ語のスイス方言)の従属節中には、統語的にcross-serial dependencies(連続交差依存)が成り立ち、これにより自然言語には文脈自由文法では作れない表現が存在することが示されました。
cross-serial dependenciesとは、以下のような(ここでは連続する動詞と対応する主格の項)の依存関係が交差しあっている状況です(文は Shieber (1985) より)。

非常に雑にいうと、依存関係が交差しないネストした(入れ子構造になっている)関係だと文脈自由文法で表現できるのですが、連続交差依存は文脈自由文法では表現できません。 たとえば、高校生の頃、英語を読むときに句や節ごとに括弧でかこんで読んでいた人は多いと思うのですが(そうですよね?)、いま考えてみると、これは英語を入れ子構造として、すなわち文脈自由レベルの文法として解析していたことになります。 もしSwiss-Germanを勉強することになっていたら、このような読み方はできなかったはずです。
cross-serial dependenciesはそうあるわけではなく、上記の文と同じ意味を日本語で表そうとすると、以下のように、依存関係は交差せず、入れ子構造になります。 cross-serial dependencies自体は確かに頻度は多くはないですが (e.g., Ferrer i Cancho et al., 2018)、存在しないわけではないので、自然言語の文法を文脈自由文法で済ますのは不十分であるといえます。
ちなみに、同時期に Culy (1985) にて、Bambaraを用いて、形態的にも文脈自由文法で表現できない事例が存在することが示されています。
241212追記:Bambaraの例は音調的な振る舞いに依存しており、形態論の問題なのか?、という議論があるようで、結局、アイヌ語にて形態論レベルでのbeyond context-freenessが示されたようです (Sanuma and Aizawa, 2024)。
2. 数多くの(独立に提案された)文法理論が、弱文脈依存文法である。
Joshi et al. (1975) によるTree Adjoining Grammar(TAG; 木接合文法)をはじめ、多くの文法理論が、特に80-90年代にかけて、計算・数理言語学の分野で提案されましたが、そのほとんどが最終的に文脈自由文法と文脈依存文法の間にいることが示されました。 これは、多くの計算・数理言語学者の間である種の「合意」がとれた状況とも言えるでしょう。
これについては、Stabler (2013) にてわかりやすくレビューされていますので、少々長いですが引用して提示しておきます。
Stabler (2013); p.4より
In particular, a very significant computational consensus was identified by Joshi (1985) in his hypothesis that human languages are both strongly and weakly mildly context sensitive (MCS). While any empirical test of this hypothesis still depends on a network of theoretical assumptions, the claim is so fundamental that it can be connected to many diverse traditions in grammar. To say that language is "strongly and weakly" MCS is to say that MCS grammars can both define the sentences of human languages (weak adequacy) and also provide the structures of those languages (strong adequacy). Joshi’s original definition of MCS grammars was partly informal, so there are now various precise versions of his claim. One is that human languages are defined by tree adjoining grammars (TAGs) or closely related grammars, and another theoretically weaker (and hence empirically stronger) position is that human language are definable by the more expressive (set local) multi-component TAGs or closely related grammars. The most remarkable thing about this claim came out of the innocent-sounding phrase "or closely related grammars," because it was discovered that a wide range of independently proposed grammar formalisms falls under that description. In particular, a series of papers beginning in the 1980’s and 1990’s established the following inclusion relations among the languages defined by various kinds of grammars, across traditions: CFG ⊂ CCG = TAG ⊂ MCTAG = ACG = MCFG = MG ⊂ CSG上記引用にて、
- CFGはContext-Free Grammar(文脈自由文法)
- CCGはCombinatory Categorial Grammar(組合せ範疇文法; Ades and Steedman (1982); Steedman (1996))
- TAGはTree Adjoining Grammar(木接合文法; Joshi et al. (1975))
- MCTAGはMulti-Component Tree Adjoining Grammar(Joshi (1987))
- ACGはAbstract Categorial Grammar(de Groote (2001))
- MCFGはMultiple Context Free Grammar(多重文脈自由文法; Seki et al. (1991))
- MCFGはLCFRS(Linear Context Free Rewriting System; Vijay-Shanker et al. (1987))と同一。
- MGはMinimalist Grammar(Stabler (1997); Stabler (2011))
- CSGはContext Sensitive Grammar(文脈依存文法)
を指します(定訳があるものは定訳を、また、その文法が提案されている代表的な論文情報を付与しています)。
また、このほかにも、
- Linear Indexed Grammar(LIG; Pollard (1984))
- Head Grammar(HG; Gazdar (1985))
も、弱文脈依存文法の仲間であることが示されています (Vijay-Shanker and Weir, 1994)。
ただ、ここで面白いのは、弱文脈依存文法は一枚岩ではなく、上記の Stabler (2013) の引用の最後の関係式で表されているように、2つのクラスに分類できます。 具体的に、CCG, TAG, LIG, HGと、MCTAG, ACG, MCFG, LCFRS, MGです(MGにも複数の亜種があります)。
その後の議論については、たとえば Stanojevic and Steedman (2020) や Frank and Hunter (2021) なども。
もちろん、各文法理論内でも、「どのような操作を仮定するか」で揺れはあるので、上記の関係が必ずしも成り立つとは限りません。たとえばCCGは、slash-typingを導入することで(=組合せ規則の適用に制限をかけることで)、TAGよりも弱生成力が低くなることも示されています (Kuhlmann et al., 2015)。
また、Head-driven Phrase Structure Grammar (HPSG; Pollard and Sag (1994)) やType Logical Grammar (TLG; 適切な引用がわからないのでSEPへ) のような、チューリング完全な文法理論もあります。
弱文脈依存文法の心理的妥当性
上記のような議論ほど有名ではありませんが、最近では、計算心理言語学の分野においても、弱文脈依存文法 (MCSG) の文脈自由文法 (CFG) に対する優位性は主張されています。 たとえば、Brennan et al. (2016) や Li and Hale (2019) はMGとCFGを比較して、Stanojevic et al. (2023) はCCGとCFGを比較して、それぞれMCSGであるMG, CCGの方が、CFGよりも適切に、人が物語を聞いている間のBOLD信号(Blood Oxygen Level Dependent signals; 脳活動を反映した信号)を予測できることを示しました。
もちろん、Hale et al. (2022) で指摘されているように、こうした結果は必ずしもMCSGが uniquely the right theory of human grammar (Hale et al., 2022; p.12) であるということを意味しているわけではありませんが、MCSGが、人間の文処理に関して、CFGでは説明できていないところを説明できているのは確かです。
そもそもの用語説明:弱生成力と強生成力
ここまで特に断りなく使っていましたが、「生成力(generative capacity)」といったとき、「弱生成力 (weak generative capacity)」と「強生成力 (strong generative capacity)」という2つの概念があります (Chomsky, 1965; 福井・辻子, 2017; 日本語訳)。
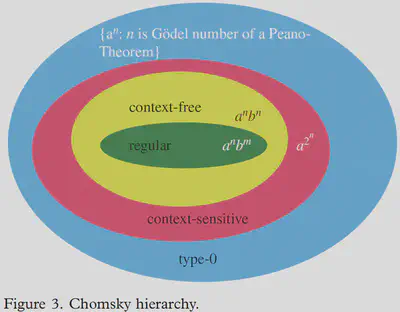
弱生成力は、ある文法が作ることのできる文字列(単語の配列)の集合に関する概念で、文法の弱生成力が等しいかつ語彙が等しい言語同士では、作ることのできる文字列の集合は完全に一致します。 つまり、弱生成力の議論において、文法とは、「容認可能な文字列のみを受理し、容認不可能な文字列は排除する装置」のことを意味します。 チョムスキー階層(下図。図はJager and Rogers (2012)より。)という概念は、弱生成力のクラス分けに関するものです(Chomsky (1956); Chomsky and Schutzenberger (1963))。
自然言語の弱生成力の議論に関しては、Jager and Rogers (2012), Hunter (2020), Roger Levyの計算心理言語学の授業のWeek 7 あたりが良かったです。
強生成力は、ある文法が作ることのできる木構造の集合に関する概念であり、Chomsky自身は弱生成力ではなく強生成力を研究の対象とするべし、としました。 木構造は(ほぼすべての理論において)意味や韻律の理論と直接関わるので、単に容認可能な文字列を識別する装置を考えるのでは不十分だ、ということでしょう。 ただ、強生成力それ自体に明確な定義があるわけではなく、そのために理論ニュートラルな議論が難しくなっている、というのが現状です。 私が知らないだけかもしれませんが、Chomskyを中心とした主流生成文法においても、強生成力の議論がなされている、というイメージはないです。
もちろん、強生成力についての議論はまったくないわけではなく、最近では、CCGとTAGが弱生成力だけではなく、強生成力においても等価である、と主張されています (Schiffer and Maletti, 2021)。
歴史概要:自然言語は文脈自由文法で表現できるのか?
cross-serial dependency は日本語にあるのでしょうか。
respectively読みの話や、GazdarらによるGPSGの提案など、Shieber (1985) までの話を書きたかった(というかこれがメインだった)はずだが、力尽きたので一旦おいておきます。

おわりに:
ここまで、自然言語の文法の弱生成力に関する議論について見てきましたが、そうはいっても本当に自然言語は弱文脈依存なのでしょうか。 実はここまでの議論は、Chomsky (1957) で指摘されているように、「文法が有限個」という暗黙の前提を置いた上での議論です。 考えてみれば当たり前の話で、観測したすべての自然言語の文を「記述」したいと思ったとき、それらの文以下の数の有限状態オートマトンさえ準備すれば、目的は達成されるかもしれません。 さすがに「そんな記述がしたいわけではない」と言われて終わりな話ですが、自然言語には部分的に正規言語っぽい部分があるのも事実です(具体的に、日本語の助動詞などまさに正規言語でしょう。古文の助動詞を思い出すとわかりすい気がします)。
また、正規言語で自然言語を語るのはさすがに厳しそうに思われますが、文脈自由文法は実際に自然言語の記述に広く使われています。 例えば、Penn Treebank (Marcus et al., 1993) はまさに文脈自由文法によるアノテーションであり、多言語に拡張されているところを見る限り、(実用上)大きな問題は生じていないようです。 同様に、Universal Dependencies (UD) (Nirve et al., 2020) においても、(依存関係が交差していない木をprojective、交差している木をnon-projectiveというのですが、)他言語においてもほとんどの木がprojectiveであると報告されています。つまり、UDコーパスのほとんどは文脈自由文法で記述できているということです。
一方で、extraposition from NPやheavy NP shift、scramblingといった構文は、分析の仕方にも依りますが、非常に文脈依存性を感じるところではないでしょうか。 Extraposition from NPとは、たとえば The man fell into the pit who had been chased by dogs. のような文で、ここで、The man とそこにかかる関係節 who … の間に動詞句 fell into the pit が入っている構造です。 Scramblingは、日本語でよくある、 花子に太郎が会った。 のような、名詞句の語順が通常と入れ替わった状態のものです。
また、Stabler (2004) では、英語においてもcross-serial dependenciesは存在している主張されています(画像はStabler (2004; p.701) より)。

個人的には、CCGやMGによる人間の文処理のモデリング研究から計算言語学・計算心理言語学の勉強を始めた人間なので、弱文脈依存仮説は「記述研究で示されているのならそういうもの」と理解して、それから「ではなぜ自然言語は弱文脈依存なのか?」ということを考えています。が、言語を使用する際には(プッシュダウン)オートマトンっぽく使っているなぁ、正規言語〜文脈自由文法っぽく理解しているなぁという直感や、cross-serialは必ずしも処理が難しいとは限らない (Bach et al., 1986) という事実、non-projectivityはむしろ処理をしやすいようにという圧力から来ているかも、というモデリング結果 (Yadav et al., 2022) から見ると、もっと使用の観点から文法の複雑さについて考えないといけないよなぁとか、そもそもここでの「文法の複雑さ」はどれだけ意味のある見方なのかなぁなんて思うときはあります。
生成力は「最悪のケース」に関する議論である一方、人間の逐次的な処理における「複雑さ」は人間の記憶や予測における平均的な認知負荷を捉えており、弱文脈依存性に関する議論を、後者の方から再検討すべきだよな、とは直観しています。
Kohei Kajikawa
Master’s student at the University of Tokyo (UTokyo).
My research interests include computational linguistics and computational psycholinguistics.